
Over the last decade, DevOps reshaped how software is built and delivered, enabling faster releases, automated pipelines, and shared ownership between development and operations.
According to Google’s DORA research, high-performing DevOps teams deploy code up to 208x more frequently and recover from failures 106x faster than low performers.
But as organizations move beyond traditional applications and start deploying machine learning at scale, a new reality sets in.
ML systems behave very differently from standard software. Models degrade over time, data changes, and performance can drift silently in production. In fact, Gartner estimates that over 50% of ML models never make it to production due to operational complexity and lack of governance.
This is where MLOps (Machine Learning Operations) comes in.
At Obsium, working closely with cloud-native, Kubernetes-first, and observability-driven platforms, we consistently see engineering teams grappling with the same questions:
Is MLOps just DevOps with models?
Do we actually need a separate MLOps strategy?
Let’s break it down.
Here’s a more engaging, narrative style version that still stays crisp and technical:
What Is DevOps?
DevOps is the operating system of modern software teams. It brings developers and IT operations together to ship applications faster, more reliably, and at scale by turning manual work into repeatable, automated workflows.
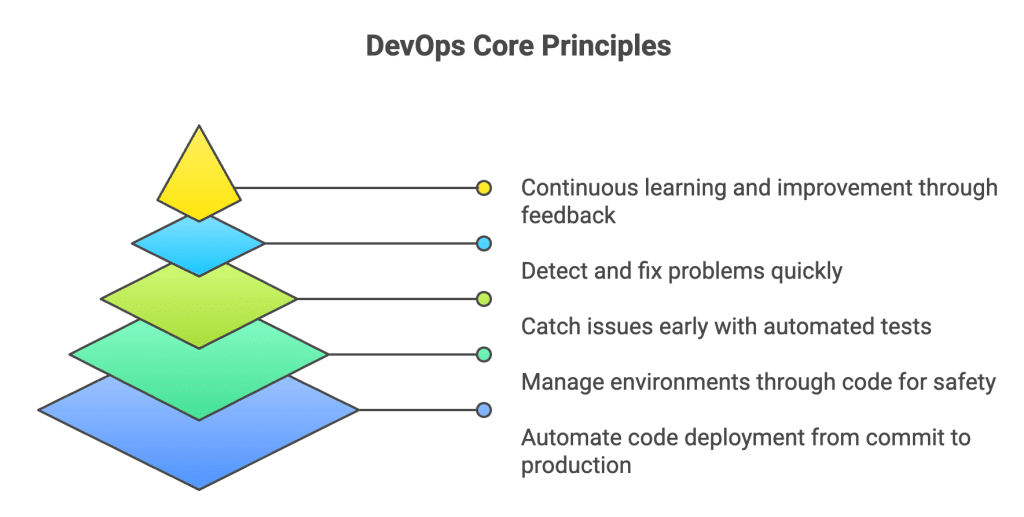
At its core, DevOps is built around a few non-negotiables:
- CI/CD pipelines that move code from commit to production automatically
- Infrastructure as Code (IaC) so environments can be created, changed, and rolled back safely
- Automated testing to catch issues early
- Monitoring and incident response to detect and fix problems fast
- Tight feedback loops that keep teams learning and improving continuously
DevOps shines when software behaves in a predictable way.
- If the code doesn’t change, the behavior doesn’t change.
- If the inputs stay the same, the outputs stay the same.
- If something breaks, you roll back and you’re back in a known state.
In simple terms, DevOps is built on one core assumption:
Same code + same inputs = same behavior.
And that assumption is exactly where things start to change when machine learning enters the picture.
Here’s a more compelling, easy-to-grasp version that clearly contrasts with DevOps and sets up the difference:
What Is MLOps?
MLOps applies DevOps principles to machine learning systems but with one critical difference: the operating environment is no longer predictable.
In traditional software, the same code behaves the same way every time. In machine learning, behavior is probabilistic, not deterministic. Outcomes change as data changes, even when the code stays exactly the same.
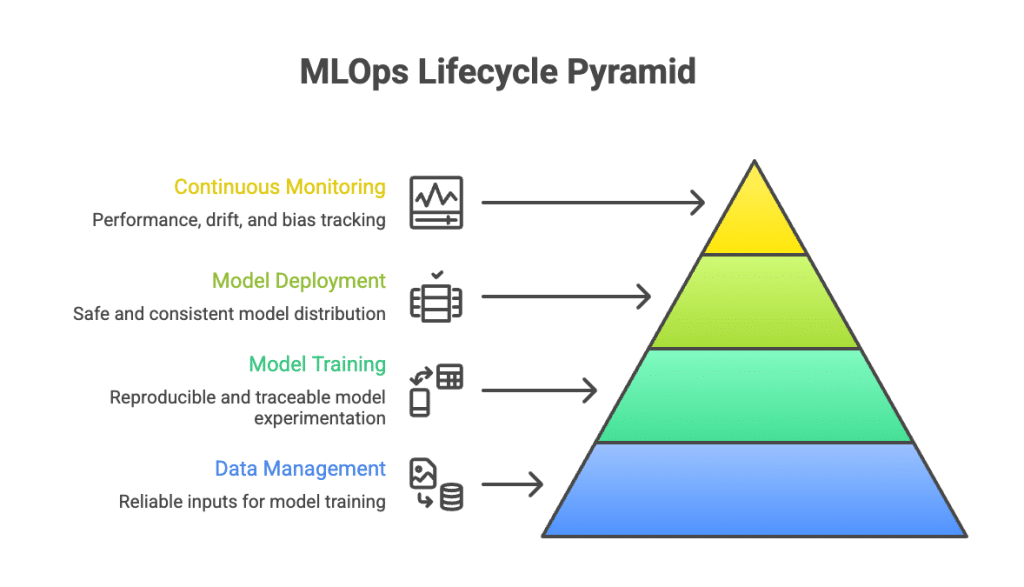
In ML systems:
- Models depend on data as much as code
- Predictions are based on probabilities, not fixed rules
- Accuracy can slowly degrade as real-world data shifts
- Failures often go unnoticed until business metrics start dropping
MLOps exists to manage this complexity across the entire machine learning lifecycle, not just deployment.
It covers:
- Data ingestion, versioning, and validation to ensure models train on reliable inputs
- Model training and experimentation with reproducibility and traceability
- Model deployment across environments safely and consistently
- Continuous monitoring for performance, drift, and bias, followed by retraining when needed
In short, while DevOps keeps software stable, MLOps keeps learning systems trustworthy in production.
DevOps vs MLOps: The Core Differences
| Dimension | DevOps | MLOps |
|---|---|---|
| Primary asset | Code | Data, models, and code |
| System behavior | Deterministic | Probabilistic |
| Failure detection | Errors, crashes, exceptions | Accuracy decay, data drift, model drift |
| Versioning | Code versions | Data versions and model versions |
| Rollback | Simple and immediate | Often requires retraining or rollback to a previous model |
| Monitoring | CPU, memory, latency, uptime | Data quality, drift, bias, and model performance |
| Feedback loop | Fast and direct | Slow, delayed, and often indirect |
Here’s a sharper, insight led version that feels like an overlooked truth rather than a textbook explanation:
The Shift No One Talks About: From Code Drift to Data Drift
In DevOps, failure announces itself.
- Services crash.
- Latency spikes.
- Error rates shoot up.
Something breaks, alarms go off, and engineers respond.
MLOps fails very differently.
Nothing crashes. Nothing times out. The system looks healthy on the surface but underneath, it’s quietly getting worse.
- Predictions become slightly less accurate every week.
- The data feeding the model no longer reflects reality.
- Business outcomes slip long before any alert is triggered.
This is the uncomfortable shift most teams underestimate. You’re no longer fighting broken systems, you’re fighting changing reality.
And that’s why observability matters more in MLOps than it ever did in DevOps. Not just infrastructure metrics, but deep visibility into data quality, drift, and model behavior in production.
Because in MLOps, by the time a problem is obvious, it’s already expensive.
Got it. Let’s make it feel alive, opinionated, and scroll-stopping.
Where DevOps and MLOps Actually Collide
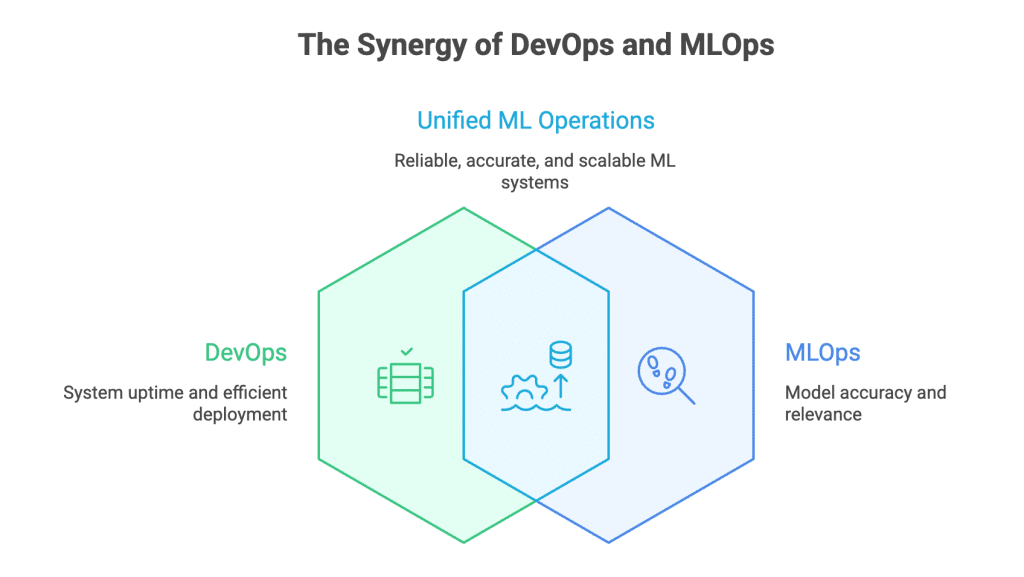
MLOps doesn’t show up to replace DevOps.
It shows up after DevOps has done its job and starts asking uncomfortable questions.
- You can have perfect CI/CD.
- Rock-solid Kubernetes.
- Beautiful dashboards full of green checkmarks.
And your ML system can still be making worse decisions every day.
That’s because MLOps isn’t about keeping systems up. It’s about keeping decisions right.
Both worlds share the same backbone:
- Kubernetes to run and scale workloads
- CI/CD pipelines to ship changes safely
- Infrastructure as Code to keep environments reproducible
- Logs, metrics, and traces to understand what’s happening
But once machine learning enters production, DevOps hits its ceiling.
Now you need to answer things DevOps never had to:
- Which dataset trained this model?
- Why did accuracy drop without a single error?
- Which experiment is actually driving revenue?
- When should this model be retrained automatically?
That’s where MLOps steps in with entirely new muscles:
- Feature stores to keep data consistent
- Experiment tracking to compare outcomes, not builds
- Model registries to manage living artifacts
- Drift detection to catch silent decay
- Automated retraining pipelines to keep systems relevant
If you remember just one line, make it this:
DevOps keeps the lights on.
MLOps makes sure the system still knows what it’s doing.
The Obsium Perspective: Observability Is the Real Convergence Point
At Obsium, we don’t see DevOps, SRE, and MLOps as separate disciplines anymore. We see them collapsing into a single operational truth:
If you can’t observe it, you can’t run it.
This gap shows up most clearly in machine learning systems. Traditional observability stops at infrastructure health. CPUs look fine. Memory is stable. Pods are green.
And yet the system is making worse decisions.
For ML workloads, observability has to move up the stack. Far up.
Beyond CPU and memory, teams need visibility into:
- How input data distributions are changing in production
- Whether model confidence is degrading over time
- How prediction latency behaves under real load
- How model outputs are actually impacting business metrics
This is why modern observability stacks aren’t a nice to have in MLOps, they’re the foundation.
- Prometheus and Grafana for metrics you can trust
- OpenTelemetry for end to end signal correlation
- eBPF based instrumentation to see what systems are really doing under the hood
Without this level of visibility, MLOps turns into guesswork. With it, teams can finally operate ML systems with the same confidence they expect from production software.
Final Thoughts
DevOps taught teams how to ship software reliably.
MLOps forces teams to confront a harder truth: software is no longer the most unpredictable part of the system.
Data changes. Models age. Reality drifts.
If you treat machine learning like traditional software, it will quietly fail while everything looks “healthy.” That’s why MLOps isn’t a trend or a rebrand. It’s an operational necessity for any team putting ML into production.
The teams that get this right won’t just deploy models faster.
They’ll know when to trust them, when to question them, and when to retrain them.
And as DevOps, SRE, and MLOps continue to converge, one principle will matter more than any tool or framework:
If you can’t observe it, you can’t operate it.


