
Machine learning teams rarely fail because they can’t train a model. They fail because everything around the model becomes chaos: inconsistent environments, fragile handoffs, duplicated pipelines, unreproducible results, and deployments that never quite behave the same way twice. As teams grow, those issues compound into operational risk.
Kubeflow exists to solve that problem by making ML workflows first-class citizens on Kubernetes. It provides a Kubernetes native set of components for training, orchestration, serving, and experimentation so ML teams can ship reliably and platform teams can operate ML like any other production workload: standardized, reproducible, and governed.
What is Kubeflow?
Kubeflow is an open source Kubernetes ML platform that helps teams run end to end ML workflows on Kubernetes. It doesn’t replace your models, frameworks, or data stack. It provides the operational layer that turns “ML code in a notebook” into repeatable pipelines that can run at scale with clear lineage, access control, and production grade deployment patterns.
At its best, Kubeflow is a platform blueprint: a set of Kubernetes controllers and services that lets you define ML workloads as containers and run them as controlled, auditable, scalable processes.
Why Kubeflow Exists?
Kubernetes standardized how enterprises run applications. ML, however, introduced a different shape of workload:
1. ML workloads are not just apps
They are multi stage systems that involve data processing, training, tuning, validation, packaging, and serving, often with expensive compute and bursty demand.
2. ML introduces reproducibility and governance requirements
You need to know which data, code, parameters, and environment produced a model, not just that the service is up.
3. Teams need a shared operational substrate
Most organizations reach a point where every team builds its own pipeline glue, its own training job scripts, and its own deployment approach, causing fragmentation that platform engineering eventually has to support.
Kubeflow exists because enterprises needed a Kubernetes native way to standardize MLOps on Kubernetes without locking into a single cloud vendor or a monolithic ML suite.
What Problem Kubeflow Solves in Modern ML Infrastructure
Kubeflow is most valuable when ML is no longer a side project and starts behaving like production software with compliance, reliability, and cost pressure.
1. Standardization across teams
Kubeflow provides common primitives and workflow patterns so teams can ship models using the same pipeline framework, training interfaces, and deployment path.
2. Scale without bespoke orchestration
Instead of inventing custom job runners, queueing logic, and GPU scheduling scripts, teams leverage Kubernetes scheduling and Kubeflow operators.
3. Reproducibility and traceability
Pipelines, metadata, and artifacts create a trail from experiment to deployed model, making audits and incident response realistic rather than forensic archaeology.
4. Platform engineering alignment
Kubeflow fits organizations that want “MLOps on Kubernetes” to be an extension of the same platform controls they already use: RBAC, namespaces, network policies, GitOps, observability, and cost governance.
How Kubeflow Architecture Works
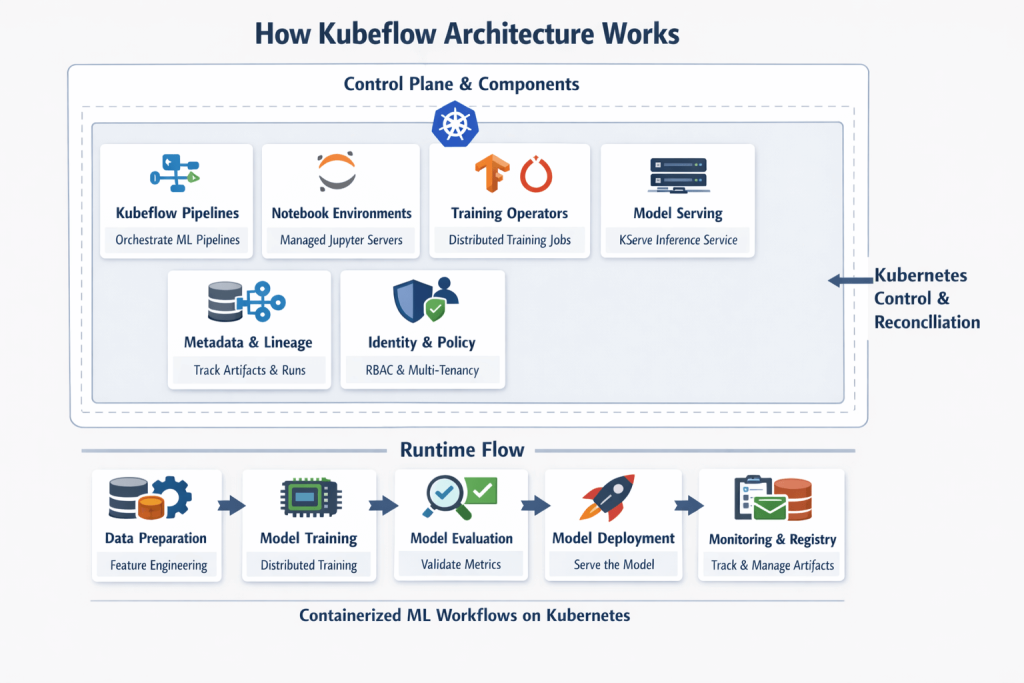
Kubeflow is not one binary. It is a collection of Kubernetes native services and controllers that work together on a cluster. The architectural principle is consistent: ML workloads are expressed as containers and custom resources, and Kubernetes reconciles desired state.
Control plane and components
Kubeflow typically includes:
1. Kubeflow Pipelines
A workflow engine for defining and running multi step ML pipelines. Pipeline steps are containerized components. The orchestration layer schedules them on Kubernetes, tracks execution, and stores metadata about runs and artifacts.
2. Notebook environments
Kubeflow can provide managed notebook servers in cluster, usually based on Jupyter, with identity integration and access controls. In enterprise deployments, these are treated like ephemeral dev environments governed by policy.
3. Training and batch job operators
Kubeflow supports distributed training through Kubernetes operators (for example, for PyTorch or TensorFlow). These operators manage the lifecycle of training jobs, including workers, parameter servers or collective training modes, retries, and resource allocation.
4. Model serving
Kubeflow commonly integrates with serving layers such as KServe for real time inference, supporting canary rollouts, autoscaling, and standardized inference endpoints.
5. Metadata and artifact lineage
Kubeflow Pipelines stores execution metadata about pipeline runs and can integrate with artifact storage, model registries, and experiment tracking. This is critical for reproducibility and governance.
6. Identity, policy, and multi tenancy
In enterprise setups, Kubeflow is often deployed with strict namespace boundaries, RBAC, and network policies. Multi user setups typically integrate with OIDC or enterprise SSO.
7. The runtime flow
A common production flow looks like this:
- Data prep and feature generation jobs run as pipeline components
- Training jobs run via training operators with GPU or distributed compute
- Evaluation steps validate metrics and model quality gates
- Packaging and registration steps publish model artifacts
- Deployment steps promote models to serving with controlled rollout policies
The key is that each step is containerized, versionable, and runs inside a governed Kubernetes execution environment.
Real World Enterprise Use Cases
Kubeflow shines in organizations that treat ML as a platform capability rather than a collection of ad hoc projects.
1. Large scale batch training on shared GPU clusters
Financial services, marketplaces, and ad tech commonly consolidate GPU capacity into Kubernetes clusters. Kubeflow operators allow teams to submit distributed training jobs while the platform team governs quotas, priority, and scheduling.
2. Standardized pipelines across multiple product teams
Enterprises with many ML teams often struggle with “pipeline sprawl.” Kubeflow Pipelines enables reusable components, templates, and policy driven deployments that reduce duplicated effort.
3. Hybrid and multi cloud ML platforms
If an organization runs Kubernetes across on prem and multiple clouds, Kubeflow provides a consistent Kubernetes ML platform abstraction, reducing dependence on any single cloud’s managed ML environment.
4. Regulated environments needing lineage and controls
In healthcare, insurance, and banking, traceability is not optional. Kubeflow’s pipeline metadata and integration capabilities help build auditable ML processes that connect data, code, and deployments.
5. Platform engineering owned ML enablement
Organizations with strong platform engineering teams often want MLOps on Kubernetes to follow the same operational discipline as microservices. Kubeflow fits that model because it aligns with Kubernetes primitives and SRE practices.
When Not to Use Kubeflow
Kubeflow is powerful, but it is not lightweight. There are clear scenarios where it is a poor fit.
1. You do not run Kubernetes as a mature platform
If Kubernetes is still a learning curve for the organization, adding Kubeflow can amplify complexity rather than reduce it.
2. Your ML workflows are small and infrequent
If training is occasional and deployments are rare, the cost of standing up and operating Kubeflow will outweigh the benefits. A simpler stack with MLflow and CI workflows may be enough.
3. You need a fully managed experience with minimal ops
If the organization wants zero infrastructure overhead, a managed service like SageMaker may be a better fit, even with trade offs in portability.
4. Your primary need is experiment tracking, not platform orchestration
If the biggest gap is tracking runs and artifacts, MLflow might solve the problem without introducing an entire Kubernetes ML platform.
Kubeflow vs Traditional ML
Traditional ML delivery often grows organically: notebooks, scripts, shared servers, and manual deployments. It works until the first incident, the first team handoff, or the first scale event.
Key differences
| Capability | Traditional ML Setup | Kubeflow on Kubernetes |
|---|---|---|
| Workflow orchestration | Glue scripts, cron, ad hoc tooling | Pipelines with reusable components and run tracking |
| Scaling training | Manual provisioning, dedicated clusters | Kubernetes scheduling plus distributed training operators |
| Reproducibility | Fragile, environment drift common | Containerized steps, versionable pipelines, metadata |
| Deployment | One off services, inconsistent patterns | Standardized serving workflows and rollout strategies |
| Governance | Difficult to enforce across teams | RBAC, namespaces, policy driven controls |
| Portability | Tied to servers and bespoke infra | Kubernetes native, portable across clusters |
Kubeflow is not just “more automation.” It is a shift from project level ML ops to platform level ML operations.
Kubeflow vs MLflow
This comparison is common because both appear in MLOps discussions, but they solve different layers of the stack.
Mental model
MLflow is primarily an experiment tracking and model lifecycle toolkit. Kubeflow is a Kubernetes ML platform for orchestrating pipelines, training, and serving. They can be used together.
| Aspect | Kubeflow | MLflow |
|---|---|---|
| Primary focus | End to end MLOps on Kubernetes | Experiment tracking and model management |
| Orchestration | Kubeflow Pipelines plus Kubernetes | Not a full workflow orchestrator by default |
| Training at scale | Distributed training via operators | Depends on your compute and integration |
| Serving | Typically via KServe and Kubernetes | MLflow model serving exists but often not Kubernetes native by default |
| Portability | Strong if you standardize on Kubernetes | Strong at the model layer, infra depends on deployment choice |
| Best fit | Platform teams enabling many ML teams | Teams needing tracking, registry, packaging workflows |
In practice, many enterprises use MLflow for tracking and registry while using Kubeflow for pipeline orchestration and Kubernetes based execution.
Kubeflow vs SageMaker
SageMaker is a managed ML platform tightly integrated with AWS. Kubeflow is open source and Kubernetes native. The right choice depends on platform strategy, governance needs, and tolerance for operational ownership.
| Aspect | Kubeflow | SageMaker |
|---|---|---|
| Operating model | You run and operate it | AWS managed services |
| Portability | High across Kubernetes environments | AWS centric |
| Speed to initial value | Slower, requires platform build | Faster for many teams |
| Enterprise controls | Leverages Kubernetes controls | Leverages AWS IAM, VPC, AWS governance tooling |
| Customization | High | High but within AWS boundaries |
| Cost profile | Infra plus ops overhead | Service pricing plus AWS infra costs |
If your organization has committed to AWS and prefers managed services, SageMaker can be pragmatic. If your platform strategy is Kubernetes first, hybrid, or multi cloud, Kubeflow aligns better.
Benefits and Trade-offs
Benefits
1. Kubernetes native standardization
Kubeflow makes ML workloads behave like other platform workloads: declarative, scheduled, observable, and governed.
2. Scalable training and serving
Distributed training and standardized serving are built around Kubernetes primitives, avoiding bespoke compute orchestration.
3. Strong platform engineering alignment
RBAC, multi tenancy, network policy, GitOps, and observability integrate naturally into Kubeflow deployments.
4. Portability and reduced vendor lock in
Kubeflow runs wherever Kubernetes runs, which matters for hybrid enterprise environments.
Trade offs
1. Deployment complexity
Kubeflow can be heavy. A production deployment often requires careful choices around networking, identity, storage, GPU scheduling, ingress, and multi tenancy.
2. Operational overhead
You are operating a platform, not a tool. Upgrades, component compatibility, security patching, and incident response become a platform responsibility.
3. Team maturity requirement
Kubeflow works best when platform engineering and ML teams have strong operational habits: containerization discipline, CI and GitOps practices, and an agreed model lifecycle process.
4. Integration work is unavoidable
Kubeflow does not magically solve data, features, governance, or registry decisions. Enterprises still need to integrate with data platforms, feature stores, model registries, and observability systems.
Deployment Complexity Considerations
Kubeflow in enterprise contexts usually fails or succeeds based on operational design, not ML features.
1. Cluster and tenancy strategy
Decide early whether you will run a shared multi tenant cluster or dedicated clusters per org unit. Multi tenancy requires stronger policy controls and clear quotas.
2. Identity and access control
Kubeflow needs to align with enterprise SSO. Without integrated identity and RBAC, you will struggle with governance and auditability.
3. Storage and artifact management
Training outputs, datasets, and pipeline artifacts require durable storage with lifecycle policies. Object storage integration is usually essential.
4. GPU scheduling and resource governance
If you run GPUs, you need clear scheduling policies, quotas, and cost visibility. Otherwise, ML workloads will destabilize shared clusters.
5. Observability and incident response
Treat ML pipelines like production workloads: logs, metrics, traces, run metadata, and alerting for failures and drift in operational KPIs.
Conclusion: Kubeflow as a Strategic Platform Choice
Kubeflow is best understood as a Kubernetes ML platform that enables enterprises to operationalize ML with the same rigor they apply to application delivery. It reduces chaos by standardizing workflows, scaling training and serving through Kubernetes primitives, and enabling reproducibility, governance, and cost control at the platform level.
But Kubeflow is not plug and play infrastructure. It requires architectural clarity, platform engineering maturity, and disciplined operational design. The real value is unlocked when Kubeflow is implemented as part of a broader Kubernetes and DevOps strategy, not as an isolated ML experiment.
This is where platform engineering partners like Obsium come in. Obsium helps enterprises design, deploy, and operationalize Kubernetes ML platforms that align with existing DevOps, SRE, and cloud governance practices. From cluster architecture and GPU scheduling to CI/CD integration and production observability, Obsium ensures Kubeflow is not just deployed, but production ready and scalable.
For organizations already investing in Kubernetes as the backbone of infrastructure, Kubeflow can become the missing layer that turns fragmented ML initiatives into a unified, enterprise grade MLOps platform. With the right architectural foundation and operational expertise, it evolves from a tool into a strategic capability.


